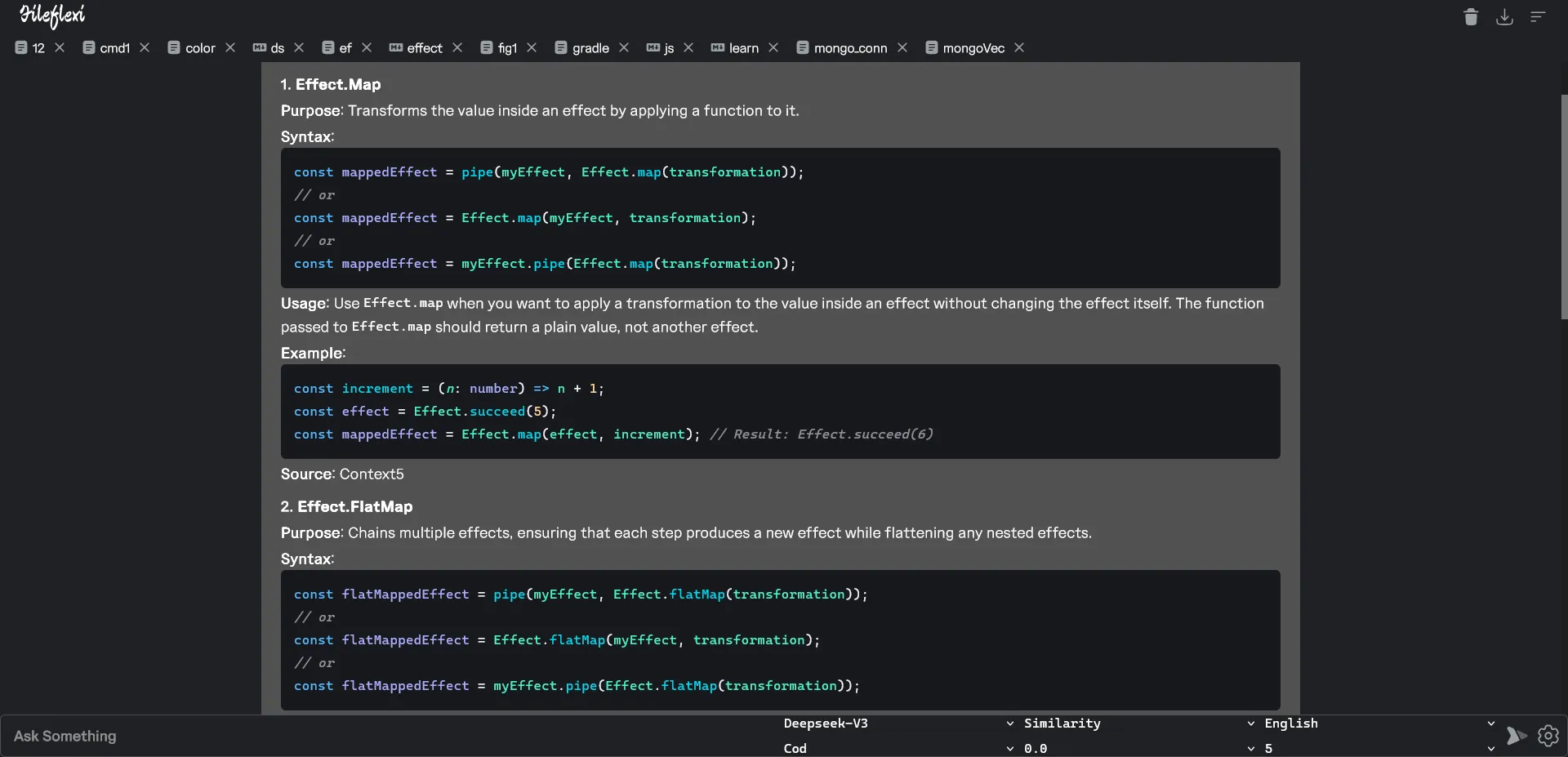
Overview
The File Extractor is a powerful tool designed to enhance Retrieval Augmented Generation (RAG) workflows by seamlessly processing various file formats into structured data that LLMs can effectively utilize.
All Kinds of LLM Support
Our File Extractor integrates with virtually any Large Language Model on the market:
- OpenAI models (GPT-3.5, GPT-4, etc.)
- Anthropic’s Claude models
- DeepSeek V3/R1
- Enterprise solutions with custom deployment options
Supported File Formats
The File Extractor handles multiple document types with intelligent parsing:
Text Files (.txt)
- Clean processing of plain text with preservation of important formatting
- Automatic detection of document structure and section boundaries
- Character encoding support across multiple languages
PDF Documents (.pdf)
- Extraction of text, tables, and metadata
- Image OCR for scanned documents
- Preservation of document hierarchy and structure
- Handling of complex layouts with multi-column support
Markdown Files (.md)
- Proper parsing of Markdown syntax
- Preservation of headings, lists, and formatting elements
- Code block extraction with language detection
- Support for embedded links and references
YouTube Transcripts
- Direct extraction from video URLs
- Timestamps and speaker attribution
- Automatic segmentation by topic
- Support for multiple languages with translation options
Customizable LLM Parameters
Fine-tune your extraction process with adjustable parameters:
- Chunk size and overlap controls
- Context window optimization
- Temperature and token settings
- Custom prompt templates
- Document segmentation strategies
- Metadata extraction preferences
- Embedding model selection
- Vector store configuration
The File Extractor serves as the foundation of a robust RAG pipeline, transforming raw content into knowledge that powers accurate, context-aware AI responses.